Hadoop安装与伪分布式集群搭建
我的环境及安装准备:VMware 15Centos 7 64
xshell 该资源来源于果核剥壳
FileZilla
jdk-8u241-linux-x64.tar.gz
hadoop-3.1.3.tar.gz
这里我是先下载jdk到本地,再通过FileZilla上传至centos的opt目录下,也可通过wget在centos下进行下载。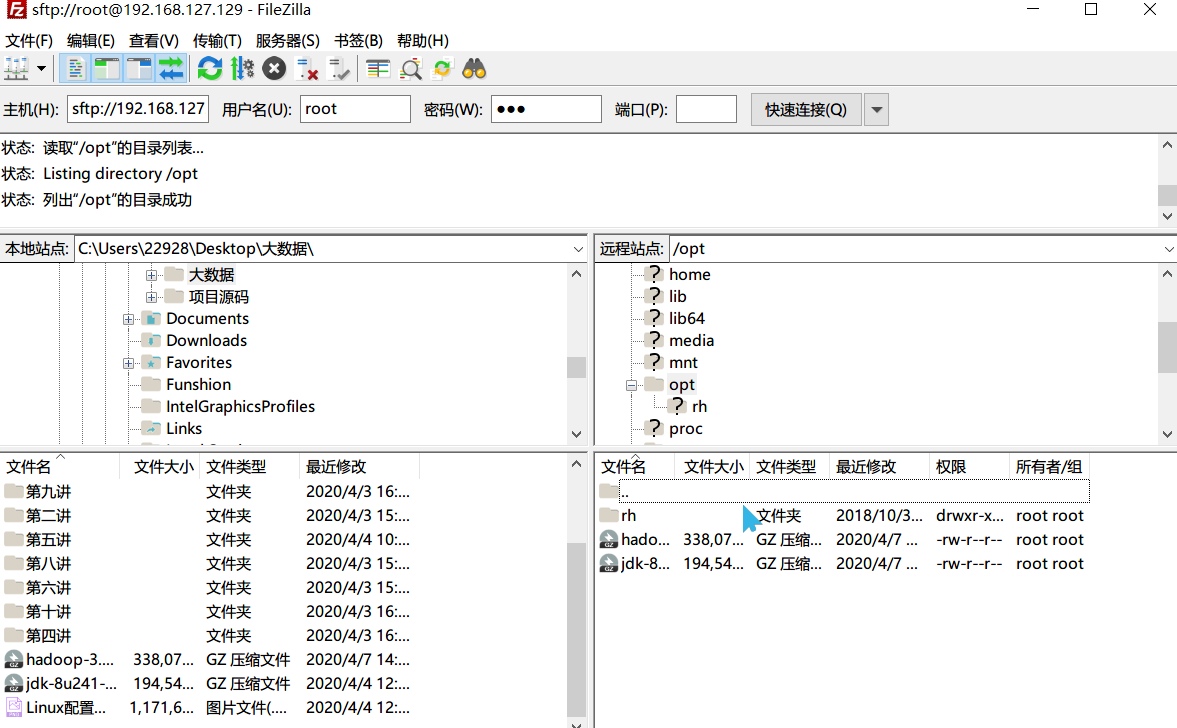
一、JavaJDK的配置
1、解压Jdk
tar -zxvf jdk-8u241-linux-x64.tar.gz -C /app/2、配置Jdk环境变量
编辑配置文件/etc/profile,并source /etc/profile使刚刚的配置生效。
在其文件底部加入以下代码:
JAVA_HOME=/app/jdk1.8.0_241
CLASSPATH=.:$JAVA_HOME/lib/tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH3、测试配置是否成功
使用javac或java -version检测是否配置成功。若未配置成功,返回以上步骤进行检查。
3、设置免密登录
3-1、检查是否安装和SSH client、SSH server
rpm -qa | grep ssh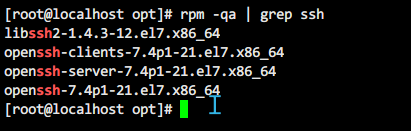
如上图就不用安装,否则,可以通过yum进行安装:
yum –y install openssh-clients3-2、测试SSH是否可用
ssh localhost
首次登陆会有提示,输入yes即可,然后按提示输入账号密码即可。
上述是没有密码登陆的方式
3-3、配置SSH无密码登陆:
输入exit回到原先的终端命令窗口,执行以下命令:
cd ~/.ssh/ #若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa #会有提示,都按回车就可以,生成密钥对:id_rsa和id_rsa.pub
cat id_rsa.pub >> authorized_keys #把id_rsa.pub追加到授权的key里面去
chmod 600 ./authorized_keys #修改文件权限3-4、启用RSA认证
vim /etc/ssh/sshd_config在# Authentication:处加入以下代码:
RSAAuthentication yes # 启用 RSA 认证
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile %h/.ssh/authorized_keys # 公钥文件路径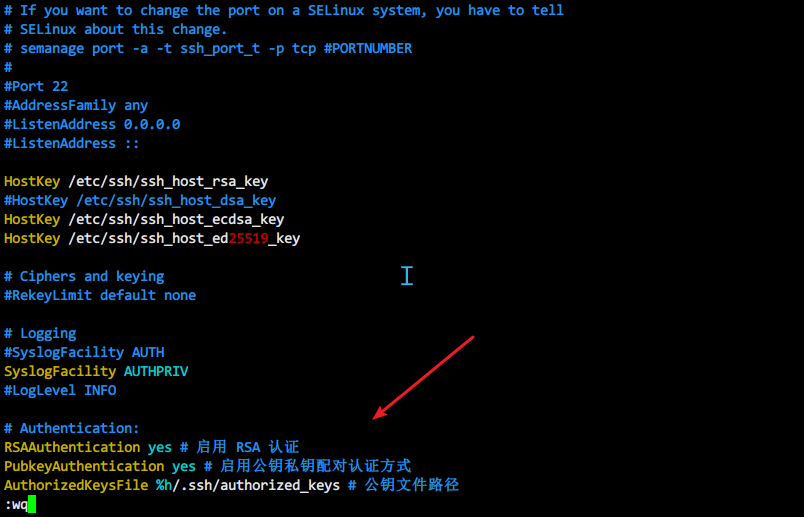
二、Hadoop安装与伪分布式集群搭建
1、解压Hadoop
tar -zxvf hadoop-3.1.3.tar.gz -C /app/2、配置Hadoop环境
2-1、配置环境变量
编辑/etc/profile,在文件末尾插入如下代码:
#set Hadoop Envirmoment
export HADOOP_HOME=/app/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin2-2、修改配置文件
a、配置root用户能启动hadoop
start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootstart-yarn.sh,stop-yarn.sh顶部需添加以下参数:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root【以上文件位置/app/hadoop-3.1.3/sbin】
【以下文件位置/app/hadoop-3.1.3/etc/hadoop/】b、hadoop-env.sh配置
在文件中插入如下代码:
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/app/jdk1.8.0_241c、yarn-env.sh配置
插入代码export JAVA_HOME=/app/jdk1.8.0_241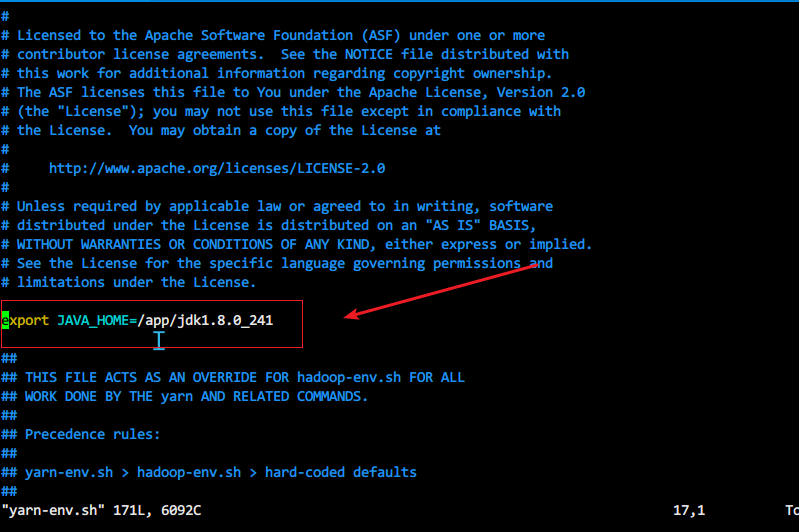
d、core-site.xml配置
在文件末尾的configuration标签中添加代码如下:
<!--配置DataNode保存数据的位置-->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!--配置HDFS的NameNode-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>e、hdfs-site.xml文件配置
在文件末尾的configuration标签中添加代码如下:
<!--配置HDFS的冗余度-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/tmp/dfs/namenode_dir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/tmp/dfs/datanode_dir</value>
</property>这里需把配置文件`hdfs-site.xml`里的``更改为``,不然后面会报错
ERROR conf.Configuration: error parsing conf hdfs-site.xml
com.ctc.wstx.exc.WstxParsingException: Unexpected close tag ; expected ......
f、mapred-site.xml文件配置
在文件末尾的configuration标签中添加代码如下:
<!--配置MR运行的框架-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>g、yarn-site.xml文件配置
在文件末尾的configuration标签中添加代码如下:
<!--配置ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!--配置NodeManager执行任务的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>2-3、创建配置文件中设置好的目录
mkdir -p /usr/local/hadoop/tmp/
mkdir -p /usr/local/hadoop/tmp/dfs/namenode_dir
mkdir -p /usr/local/hadoop/tmp/dfs/datanode_dir3、启动Hadoop
3-1、namenode格式化
hadoop namenode -format3-2、启动HDFS
start-dfs.sh3-3、启动Yarn资源管理器
start-yarn.sh3-4、启动历史服务器
mr-jobhistory-daemon.sh start historyserver3-5、jps验证
[root@localhost hadoop]# jps
10641 SecondaryNameNode
10929 ResourceManager
11508 Jps
10406 DataNode
11384 JobHistoryServer
11066 NodeManager